iPhone: Testing your Application with Valgrind
24 Dec 2008, 15:39 PSTOn other platforms, I've found valgrind to be indispensable when it comes to discovering and fixing bugs. With Greg Parker's port of valgrind for Mac OS X now available, it's now possible to test your Mac and iPhone applications with valgrind.
Valgrind does not support ARM, but it is capable of executing i386 binaries built against the iPhone Simulator SDK. The only difficulty is that you can't run valgrind from the command line -- GUI iPhone Simulator binaries must be registered and run by Xcode, which uses the private iPhoneSimulatorRemoteClient framework to start and stop Simulator sessions.
To work around this, I wrote a small "re-exec" handler in my application's main(). It looks like this:
#define VALGRIND "/usr/local/valgrind/bin/valgrind"
int main(int argc, char *argv[]) {
#ifdef VALGRIND_REXEC
/* Using the valgrind build config, rexec ourself
* in valgrind */
if (argc < 2 || (argc >= 2 && strcmp(argv[1], "-valgrind") != 0)) {
execl(VALGRIND, VALGRIND, "--leak-check=full", argv[0], "-valgrind",
NULL);
}
#endif
NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init];
int retVal = UIApplicationMain(argc, argv, nil, @"PeepsAppDelegate");
[pool release];
return retVal;
}
To enable this code, I added a 'valgrind' build configuration to my project which defines VALGRIND_REXEC. After switching to the valgrind configuration, my application will run in the Simulator, under valgrind:
[Session started at 2008-12-24 15:27:47 -0800.] ==38596== Memcheck, a memory error detector. ==38596== Copyright (C) 2002-2008, and GNU GPL'd, by Julian Seward et al.
Running our code under valgrind has greatly facilitated the resolution of otherwise difficult to find or entirely unknown bugs.
iPhone: Safari Bookbag Updated
24 Dec 2008, 15:35 PSTAn update to Safari Bookbag has been posted, using the CoverFlow implementation from Peeps to replace the previous UICoverFlowLayer implementation.
Apple appears to be getting more serious about checking for private APIs -- the previous 2.2 compatibility update to Safari Bookbag was rejected by Apple due to the continued use of UICoverFlowLayer.
Peeps Available!
21 Dec 2008, 11:29 PSTWe're dancing over here. After quite a bumpy ride, Apple has approved Peeps for distribution in the App Store.
I even have a fancy image!

I'm already hard at work on the next version -- top requested features:
- Social network integration for fetching your friends' photographs
- Ad-hoc sharing of pictures and contact information between phones
If you've got something you'd like on the list, send us an e-mail!
iPhone: Peeps Rejected for Private API ... Huh?
12 Dec 2008, 16:47 PSTUpdate
Peeps has been approved!
After waiting 33 days to receive word on our app, Peeps, we've got a reply:
Upon review of your application, Peeps cannot be posted to the App Store due to the usage of a non-public API. Usage of non-public APIs, as outlined in the iPhone SDK Agreement section 3.3.1, is prohibited: "3.3.1 Applications may only use Published APIs in the manner prescribed by Apple and must not use or call any unpublished or private APIs. " The non-public API that is included in your application comes from the CoverFlow API set.
Let's be clear here: We did not use private API.
The last thing I would do is deliver time-bomb code to a paying customer. Private API can be broken or removed at any time by the vendor, and relying on it is unfair to your customers -- they rarely have any idea that the application they just purchased may not work next week, or next month.
So when I needed a CoverFlow-like user interface I wrote my own -- from scratch. I suppose I should be flattered that Apple mistook it for their own implementation (demo 1, demo 2).
In the mean time, I've got a support request in, and I'm waiting to hear back from the App Store. I don't fault Apple for the misunderstanding, I just wish they hadn't taken 33 days to tell me.
If you're willing to brave the App Store waters and would like to license our implementation for your own app, just say hello.
Update: You can now download a demo and purchase a copy of PLJukebox (our implementation) directly from the Plausible Labs website
30 Days, App (Still) Not Approved
09 Dec 2008, 20:29 PSTUpdate
Peeps has been approved!
Apple's Lesson in Zen Patience
30 days ago, we were excited. Peeps 1.0 was finished, localized into a few languages, and submitted to the iPhone App Store for review. We even loved the icon — drawn by the talented Kelly J. Brownlee.
Most of my friend's apps were approved within a day, so after a week of waiting, I sent Apple an e-mail, to which they duly responded:
Your application Peeps is requiring unexpected additional time for review. We apologize for the delay, and will update you with further status as soon as we are able.
So we waited. An exercise in Zen — patience in the modern age. I released an update to the Plausible Database library. I finished preparing ActorKit for release. I took on some contracting work.
I sent follow-up e-mails, too. They all went unanswered. I even called Apple Developer Relations (they'll forward my query on, said the support representative. I should call for updates). So 30 days later, Peeps is still in limbo. It's not approved, nor is it rejected, it just simply is. I was fastidious in following Apple’s guidelines, used no private API, and I'm left with no idea what has triggered this state of application limbo.
What can I do? Apple doesn't answer my e-mails or phone calls, and my hard work is sitting in a queue, somewhere. I guess I write a blog post, and then try learn from this lesson in Zen.
[Addendum] - To clarify, we're not using the UICoverFlowLayer private API -- we wrote our own CoverFlow implementation (demo 1, demo 2)
iPhone: Safari Bookbag + Private API
06 Dec 2008, 12:43 PSTI occasionally use O'Reilly Publishing's Bookbag iPhone application to read my Safari Bookshelf books when I'm away from my computer (Safari Bookbag has no relation to Apple's Safari browser). Last night I was suprised to find that the Bookbag application was crashing on launch. Checking the app store application description, I found this note from O'Reilly:
This version does not work with iPhone OS v2.2. We are working on a 2.2-compatible version and will be submitting soon.
That's odd -- the most likely cause of an application breaking on a new iPhoneOS release would be if they used private API. Taking a look at the iPhone crash log, that appears to be the case:
Process: Bookbag [2386] [snip] Thread 0 Crashed: 0 libSystem.B.dylib 0x31459c58 __kill + 8 1 libSystem.B.dylib 0x31459c46 kill + 4 2 libSystem.B.dylib 0x31459c3a raise + 10 3 libSystem.B.dylib 0x31474424 abort + 36 [snip] 8 libobjc.A.dylib 0x300c1f84 objc_exception_throw + 92 9 CoreFoundation 0x302c883e -[NSObject doesNotRecognizeSelector:] + 106 10 CoreFoundation 0x30287222 ___forwarding___ + 490 11 CoreFoundation 0x3026d618 _CF_forwarding_prep_0 + 40 12 Bookbag 0x0000406c 0x1000 + 12396 13 Bookbag 0x0000463a 0x1000 + 13882 14 Bookbag 0x00004402 0x1000 + 13314
We can see here that Bookbag calls some method that triggers a call to -[NSObject doesNotRecognizeSelector:]. The 'doesNotRecognizeSelector:' message is sent by the Objective-C runtime when an object receives a message it can't respond to or forward. The doesNotRecognizeSelector method raises an exception, and the application terminates.
Objective-C methods don't simply disappear from an application, but they can disappear from a library. Private APIs are private because they may be modified or removed at any time -- if a method disappeared from one of the iPhoneOS libraries, chances are it was a private method.
To be sure that Bookbag really is using private API -- and to determine what API they used -- I decided to strip the DRM from the Bookbag application and disassemble their binary. Thanks to the crash log, we already know where to look -- address 0x406c, the last return address located in the Bookbag binary before doesNotRecognizeSelector: was triggered.
Apple's iPhone Application DRM utilizes Mach-O binary encryption to protect the application code. Briefly put, application decryption is handled by the kernel -- within a process space, the encrypted section of its Mach-O binary is automatically decrypted by the kernel as it is read. To strip the DRM from an iPhone app, one can simply attach a debugger to the application on a jailbroken phone, and dump the text section containing the program code. For a more comprehensive description of Mach-O binary encryption, read Amit Singh's article: Understanding Apple's Binary Protection in Mac OS X.
So after stripping the DRM (let's only use this power for good, not evil, yes?), I can disassemble the relevant Bookbag code and determine what private API is being called to trigger the crash. Here's my abridged annotated disassembly. (see unabridged)
-[CoverFlowView initWithFrame:andCount:]:
[snip]
0x4050 1c22 mov r2, r4 (add r2, r4, #0)
0x4052 ca0b ldmia r2!,{r0, r1, r3}
0x4054 c50b stmia r5!,{r0, r1, r3}
// argument 1 - saved pointer to @selector(initWithFrame:numberOfCovers:)
0x4056 4651 mov r1, r10
0x4058 9b09 ldr r3, [sp, #36]
0x405a 9a20 ldr r2, [sp, #128]
0x405c 9311 str r3, [sp, #68]
0x405e 9202 str r2, [sp, #8]
0x4060 ab10 add r3, sp, #64
0x4062 466a mov r2, sp
// argument 0 - UICoverFlowLayer instance
0x4064 4658 mov r0, r11
0x4066 cb30 ldmia r3!,{r4, r5}
0x4068 c230 stmia r2!,{r4, r5}
// argument 2 - value of -[UIScreen frame]
0x406a 9a0e ldr r2, [sp, #56]
// argument 3 - number of covers
0x406c 9b0f ldr r3, [sp, #60]
// Call -[UICoverFlowLayer initWithFrame:numberOfCovers] (UICoverFlow is private API)
0x406e efa8f006 blx 0xafc0 ; symbol stub for: _objc_msgSend
It's clear from the disassembly that Bookbag is using the private UICoverFlowLayer API. When Apple released iPhoneOS 2.2, the -[UICoverFlowLayer initWithFrame:numberOfCovers:] method was removed, and Safari Bookbag started crashing.
Safari Bookbag's use of UICoverFlowLayer is a discovery that has caused me some chagrin -- I held off on implementing Peeps -- which includes a fully functional CoverFlow clone -- until I saw that Apple had approved Safari Bookbag. I had assumed the authors of Bookbag implemented their own CoverFlow, too. To increase my vexation, Apple still hasn't approved Peeps nearly a month after it was submitted for review (on November 9th).
Lastly, this accutely demonstrates why one should be incredibly circumspect about using undocumented API -- it's undocumented because it can change at any time, and if it changes, your application will very likely start crashing. Even if your app slips through the cracks in Apple's review system, users will notice when your app breaks (see the Safari Bookbag reviews).
iPhone: Determining Available Memory
06 Dec 2008, 12:43 PSTThe iPhone has limited memory, and even simple applications can easily trigger a low memory warning. If you've implemented caching for performance reasons, you'll often find yourself balancing memory consumption against user experience.
Measuring the current available RAM allows one to make pre-emptive decisions about memory utilization before a low memory warning is triggered, possibly avoiding overly broad cache evictions when a memory warning is triggered.
I've seen this question come up a number of times, so here's a brief code snippet demonstrating how to determine available memory from the Mach VM statistics.
#import <mach/mach.h>
#import <mach/mach_host.h>
static void print_free_memory () {
mach_port_t host_port;
mach_msg_type_number_t host_size;
vm_size_t pagesize;
host_port = mach_host_self();
host_size = sizeof(vm_statistics_data_t) / sizeof(integer_t);
host_page_size(host_port, &pagesize);
vm_statistics_data_t vm_stat;
if (host_statistics(host_port, HOST_VM_INFO, (host_info_t)&vm_stat, &host_size) != KERN_SUCCESS)
NSLog(@"Failed to fetch vm statistics");
/* Stats in bytes */
natural_t mem_used = (vm_stat.active_count +
vm_stat.inactive_count +
vm_stat.wire_count) * pagesize;
natural_t mem_free = vm_stat.free_count * pagesize;
natural_t mem_total = mem_used + mem_free;
NSLog(@"used: %u free: %u total: %u", mem_used, mem_free, mem_total);
}
For more information, see the vm_statistics man page.
ActorKit: Objective-C Asynchronous Inter-thread Message Passing
03 Dec 2008, 00:13 PSTIntroduction
In the process of writing Peeps, I decided to implement a library to simplify handling of background processing on the iPhone. The phone itself is a somewhat limited device, and I found that background processing was required to maintain UI interactivity while loading and rendering images for Peep's portrait and CoverFlow views.
Having spent considerable time working with actor-based concurrency systems, I decided to implement a ActorKit -- an Objective-C implementation of asynchronous inter-thread message passing. You can peruse the documentation and download the 1.0-beta1 release of ActorKit from the project page
ActorKit
ActorKit is intended to facilitate the implementation of concurrent software on both the desktop (Mac OS X) and embedded devices (iPhone OS). On the iPhone, thread-based concurrency is a critical tool in achieving high interface responsiveness while implementing long-running and potentially computationally expensive background processing. On Mac OS X, thread-based concurrency opens the door to leveraging the power of increasingly prevalent multi-core desktop computers.
To this end, ActorKit endeavours to provide easily understandable invariants for concurrent software:
- All threads are actors.
- Any actor may create additional actors.
- Any actor may asynchronously deliver a message to another actor.
- An actor may synchronously wait for message delivery from another actor.
As an actor may only synchronously receive messages, no additional concurrency primitives are required, such as mutexes or condition variables.
Building on this base concurrency model, ActorKit provides facilities for proxying Objective-C method invocations between threads, providing direct, transparent, synchronous and asynchronous execution of Objective-C methods on actor threads.
Actor Creation and Simple Message Passing
Messages
The Actor model of concurrency is fundamentally based on communication between isolated actors through asynchronous message passing. In ActorKit, any Objective-C object conforming to the NSObject protocol may be used as an inter-actor message, but message objects should be immutable to ensure thread safety. ActorKit, being written in Objective-C, can not enforce message immutablity or full isolation of Actor threads. It is entirely possible to pass mutable messages, or access mutable global variables. Like many other libraries implementing Actor message passing semantics, isolation is maintained purely through convention.
While ActorKit supports messaging with any Objective-C object, the PLActorMessage class provides generally useful facilities such as unique message transaction ids, automatically determining the message sender, and including additional message payloads.
Actor Proceses
In ActorKit, all threads are fully functioning actors -- including the "main" Cocoa thread. Each actor is represented by a PLActorProcess instance, which may be passed to any other running actors, and is used to send messages asynchronously to the given process.
ActorKit ensures that all message reception within a given actor occurs serially, and provides strict guarantees on message ordering -- messages M1 and M2 sent from actor A1 will be delivered to actor A2 in the same order. However, delivery of messages from actor A1 may be interspersed with delivery of messages sent by other actors:

In the future, ActorKit may be extended to leverage Apple's Grand Central to provide hybrid event/thread M:N scheduling of actor execution on available cores, an approach presented by Philipp Haller and Martin Odersky and implemented in Scala's Actor library (LAMP-REPORT-2007-001, EPFL, January 2007)
A Simple Echo Actor
- (void) echo {
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
PLActorMessage *message;
// Loop forever, receiving messages
while ((message = [PLActorKit receive]) != nil) {
// Echo the same message back to the sender.
[[message sender] send: message];
// Flush the autorelease pool through every loop iteration
[pool release];
pool = [[NSAutoreleasePool alloc] init];
}
[pool release];
}
- (void) run {
// Spawn a new actor thread. This will return a process instance which may be used
// to deliver messages the new actor.
id proc = [PLActorKit spawnWithTarget: self selector: @selector(echo:)];
// Send a simple message to the actor.
[proc send: [PLActorMessage messageWithObject: @"Hello"]];
// Wait for the echo
PLActorMessage *message = [PLActorKit receive];
}
Sending Synchronous Messages with Actors
In an Actor system where all messages are sent asynchronously, synchronous messaging may be achieved with the following steps:
- Allocate a unique transaction id
- Send a message with that transaction id
- Wait for a reply with a matching transaction id.
Message Sequence:

ActorKit provides facilities for handling this common usage scenario. Unique transaction ids may be generated via -[PLActorKit createTransactionId] and every PLActorMessage generates and uses a new transactionId.
The PLActorRPC class utilizes the PLActorMessage's transaction id to wait for a reply on your behalf.
Send a message, and wait for the reply:
idhelloActor = [PLActorKit spawnWithTarget: self selector: @selector(helloActor:)]; PLActorMessage *message = [PLActorMessage messageWithObject: @"Hello"]; PLActorMessage *reply = [PLActorRPC sendRPC: message toProcess: helloActor];
Transparently Proxying Objective-C Messages with Actors
ActorKit provides two NSProxy subclasses which provide transparent proxying of Objective-C synchronous and asynchronous method invocations via actor messaging. PLActorRPCProxy spawns a new actor to execute Objective-C methods for a given object instance, while PLRunloopRPCProxy executes Objective-C methods on a provided NSRunLoop.
In combination, these classes allow for safely and transparenty executing methods on Objective-C instances from any thread:
NSString *actorString = [PLActorRPCProxy proxyWithTarget: @"Hello"]; NSString *runloopString = [PLRunloopRPCProxy proxyWithTarget: @"Hello" runLoop: [NSRunLoop mainRunLoop]]; // Executes synchronously, via a newly created actor thread. [actorString description]; // Executes synchronously, on the main runloop. [runloopString description];
By default, PLActorRPCProxy and PLRunloopRPCProxy will execute methods synchronously, waiting for completion prior to returning. In order to execute a method asynchronously -- allowing a long running method to execute without waiting for completion -- it is necessary to mark methods for asynchronous execution.
The Objective-C runtime provides a number of type qualifiers that were intended for use in implementing a Distributed Object system. Of particular note is the 'oneway' qualifier, which allows us to specify that a method should be invoked asynchronously.
When a method is declared with a return value of 'oneway void', the proxy classes will introspect this return value, and execute the method asynchronously, without waiting for a reply:
- (oneway void) asyncMethod {
// Execute, asynchronously
}

- (NSString *) synchronousMethod {
// Execute, synchronously
return @"Hello";
}
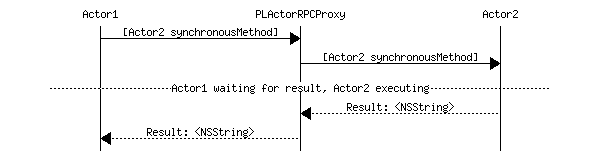
A Simple Echo Actor with PLActorRPCProxy
The following actor returns a proxy from its init method, ensuring that all methods called on the object instance will occur via the actor thread.
// An actor that responds to Objective-C messages either synchronously or asynchronously.
@implementation EchoActor
- (id) init {
if ((self = [super init]) == nil)
return nil;
// Launch our actor
id proxy = [[PLActorRPCProxy alloc] initWithTarget: self];
// Release ourself, as the proxy has retained our object,
// and return our proxy to the caller
[self release];
return proxy;
}
// Method is called asynchronously
- (oneway void) asynchronousEcho: (NSString *) text listener: (EchoListener *) echoListener {
[echoListener receiveEcho: text];
}
// Method is called synchronously
- (NSString *) synchronousEcho: (NSString *) text {
return text;
}
@end
Integration & Development Services
ActorKit is provided free of charge under the MIT license, and may be freely integrated with any application. We can provide assistance with integrating our code in your own iPhone or Mac application, as well as development of additional features under a license of your choosing. We're also available for standard iPhone and Mac OS X application development.
Contact me for more information, or visit the Plausible Labs website.
References
Actors that Unify Threads and Events, Philipp Haller and Martin Odersky, LAMP-REPORT-2007-001, EPFL, January 2007. Available from http://lamp.epfl.ch/~phaller/actors.html.
iPhone Framework Support - Shipping Libraries
02 Dec 2008, 16:42 PSTIntroduction
Due to Apple's restrictions, third party apps for the iPhone may not include embedded dynamic frameworks or libraries, necessitating the use of static libraries for implementing shared code.
To make things more difficult, iPhone projects are actually targeted at two distinct platforms: iPhoneOS (the phone) and iPhoneSimulator (the simulator). The two platforms are very different, and one can't build a universal binary for both the simulator and the phone by specifying both i386 and armv6 architectures, as you would if building a universal binary for Mac OS X.
These issues complicate shipping re-usable libraries for the iPhone, and I've struggled to find a reasonable method for releasing Plausible Database, as well as the number of other open source libraries I plan on releasing with our (yet to be approved) iPhone application, Peeps.
Now that the NDA is no longer in effect (yay), this article is intended to be the first in a (likely sporadic) series on iPhone development and to-be-released open source libraries.
Frameworks are Good
A significant advantage of frameworks over simple static libraries is the bundling of headers, the library, and any resources into an easy to install bundle -- to use a framework, simply copy it into your project and add it to your target. The include and linker paths will be automatically configured, and resource references will even be resolved to the correct file path.
One doesn't have to give up all of functionality of frameworks when developing for the iPhone -- one undocumented (and, to quote, "semi-supported") feature of framework linking is "static frameworks". Generally a framework includes a dylib -- "MyCode.framework/Versions/Current/MyCode". By replacing this dylib with a static library, the framework can be easily imported and used within an iPhone project.
Static frameworks are not a full replacement for standard frameworks -- standard methods for accessing the framework resources, such as +[NSBundle bundleForClass:], will not return the expected bundle. The bundle path is determined by querying dyld for the library path corresponding to the symbol address -- In the case of static linking, this will return the path to the binary into which the static library was linked. (see the CFBundle implementation (APSL, requires free ADC account)). Additionally, NSBundle/CFBundle will examine the previous stack from for the return address, and use that return address to determine the calling code's dyld binary path. Given these restrictions, some work-arounds are possible, such as using -[NSBundle privateFrameworkPath] to locate the path to the embedded framework.
Additionally, the iPhoneOS and iPhoneSimulator SDK specifications do not support the 'Framework' product type, meaning that the framework directory structure must be built by hand. Fortunately, frameworks are fairly simple directory structure. For Plausible Database, I simply the built Mac OS X framework, and then replacing the enclosed dynamic library with the iPhone static library. (To see where supported build types are defined, take a look at /Developer/Platforms/iPhoneOS.platform/Developer/Library/Xcode/Specifications/iPhoneOSProductTypes.xcspec on your development system.)
While static frameworks are fairly limited (by a significant margin), I've found them to be a convenient, if small, improvement on shipping standalone static libraries. Your mileage may vary.
Universal Binaries: iPhoneOS vs. iPhoneSimulator
While Mac OS X bundles (applications, etc) include support for multiple platforms:
Application.app/Contents/MacOS Application.app/Contents/Windows
frameworks do not:
MyFramework.framework/Versions/A/MyFramework
As noted earlier, iPhone projects actually target two distinct platforms -- the simulator, and the phone.
It is possible, if incorrect, to lipo together a single static library that may be used for both platforms. With such a binary, the i386 binary will be used when linking against the simulator SDK, and the armv6 binary will be used when linking against the iphoneos SDK. While this will work without error, it may break in the future. For example, if Apple ever releases an i386 based iPhone (using, for instance, the Intel Atom, then binaries intended to be used with the iPhoneOS SDK must be built armv6/x86 universal, and the result will not work when used with the simulator.
As an alternative, one can use the PLATFORM_NAME or EFFECTIVE_PLATFORM_NAME to link against a platform-specific static library; simply add -lSomeLibrary${EFFECTIVE_PLATFORM_NAME} to your target's linker options.
Conclusion
As it stands, shipping librares for the iPhone is fairly messy. Until a more approachable mechanism is provided for shipping iPhone libraries, I plan on building universal i386-simulator/armv6-iphoneos static frameworks for my open source projects and internal libraries. I might change my mind later.
In the meantime, I've filed rdar://6413456 -- RFE: Support for dylibs (and embedded frameworks) in 3rd-party iPhone apps. I'm sure it's a duplicate. =)
Darwin OpenJDK 7 Binaries
20 Aug 2008, 15:56 PDTTo help facilitate user testing, I've built and posted OpenJDK 7 binaries for Mac OS X 10.5 here:
openjdk7-darwin-i386-20080820.tar.bz2 (sig).
Help us find bugs -- give your code a try on OpenJDK 7, and send any issues along to the bsd-port-dev mailing list.
SoyLatte, Meet OpenJDK: OpenJDK 7 for Mac OS X
20 Aug 2008, 11:26 PDTIntroduction
The long-term goal of the SoyLatte project was to ensure open, timely development of Java 7 for Mac OS X, with support for all recent versions of Mac OS X.
I'm pleased to announce that OpenJDK 7 is now runnable on both Mac OS X and the BSDs, as part of the OpenJDK BSD Port. The project represents the culmination of considerable work by Greg Lewis, Kurt Miller, Dalibor Topic, and myself.
landonf@max> uname -s -r
Darwin 9.4.0
landonf@max> ./build/bsd-i586/j2sdk-image/bin/java -version
openjdk version "1.7.0-internal" OpenJDK Runtime Environment
(build 1.7.0-internal-landonf_2008_08_19_12_38-b00)
OpenJDK Server VM (build 14.0-b01, mixed mode)
Code Access
OpenJDK uses Mercurial with the Forest extension. Before checking out the BSD sources, you will need to install and configure Mercurial. See the OpenJDK Developer's Guide for more information.
To check out the BSD-Port forest:
hg fclone http://hg.openjdk.java.net/bsd-port/bsd-port
As an alpha port to an in-development code base, some bugs are to be expected. Testers are most welcome.
Building
Due to bugs in 10.4's compiler, building the sources currently requires a Mac OS X 10.5 machine.
Bootstrapping OpenJDK currently requires either SoyLatte 1.0.3, or a binary release of OpenJDK. The code base will not bootstrap against Apple's JVM.
Some portions of OpenJDK are still unavailable under an open-source license. To build OpenJDK, will also need Kurt Miller's binary plugs for the BSD port: jdk-7-icedtea-plugs-1.6.tar.gz. The binaries are derived from the IcedTea project.
To build the JDK in build/bsd-i586/j2sdk-image:
make \ ALT_BOOTDIR=/usr/local/soylatte-i386-1.0.3 ALT_BINARY_PLUGS_PATH=$HOME/jdk-7-icedtea-plugs \ ALT_FREETYPE_HEADERS_PATH=/usr/X11R6/include \ ALT_FREETYPE_LIB_PATH=/usr/X11R6/lib \ ALT_CUPS_HEADERS_PATH=/usr/include \ ANT_HOME=/usr/share/ant \ NO_DOCS=true \ HOTSPOT_BUILD_JOBS=1
Please make sure you're using the latest SoyLatte 1.0.3 release, or the build will fail.
Contributing
The move to OpenJDK -- and Sun's re-licensing of the code under the GPL license -- opens the project to any interested contributer. Some exciting areas of exploration:
- Java conformance testing with the Java JCK
- Enabling dtrace support
- PowerPC and ARM support via the OpenJDK zero project
- Implementing proper "dual-mode" support for x86-32 and x86-64 JVMs
- Java 6 implementation via the OpenJDK 6 Project
- CoreAudio Sound Support
- Improving Mac OS X Integration
If you're interested in contributing, please join the bsd-port-dev mailing list.
OpenJDK Proposal for BSD Porting Project
01 Aug 2008, 16:49 PDTWith Sun's approval to merge the BSD Java patchset to OpenJDK squared away, Dalibor Topic has proposed project sponsorship for the BSD porting project.
If sponsorship is approved, the BSD Java Port -- which includes all the Soylatte changes -- will be able to officially join the OpenJDK project. Combined with the zero-assembler port, we could see OpenJDK 6/7 support in the near future for Mac x86 and PPC machines.
I'm very excited to see OpenJDK/BSD support progressing due to the hard work Dalibor Topic, Greg Lewis, and Kurt Miller.
Plausible Labs
18 Jul 2008, 13:24 PDTJonathan and I have founded Plausible Labs, where we're now working on GIS technology and applications for the iPhone. It's our hope to heighten interest in the communities and culture around us by providing ready access to geographic information.
In addition to our standing commitment to releasing what we can as open source, we're interested in sharing the geographic data we've gathered, with the intent of encouraging the creation of a broad range of data-driven applications.
![]()
Comcast and Outgoing Port 25
18 Jul 2008, 10:49 PDTSuggestions
I've received a number of suggestions to try sonic.net. They block port 25 (as do most ISPs), but will happily remove the block upon request:
We here at Sonic.net pride ourselves at providing the WHOLE internet, not just parts. Port 25 as mentioned is the only port that we do block for individuals who reside on our network. You can go into the Member Tools section of Sonic.net and modify any of your firewall settings.
I've got a sales query pending to see what DSL speeds I can get here in Cole Valley
Thanks for the tips!
Original Post
I wouldn't normally post something like this, but my mind boggles at the thought of paying for an internet connection that's filtered by Comcast. I actually use outgoing SMTP.
When considered against Comcast's bittorrent filtering, I find this trend disturbing. Once Comcast has deep packet inspection, and is comfortable inconveniencing customers with port 25 filtering, I don't see any reason why the trend won't continue with other potentially inconvienent network protocols.
Anyone recommend an alternate internet service provider in San Francisco? Here are the support conversation highlights:
Caleb(Fri Jul 18 2008 13:38:06 GMT-0700 (PDT))> First, and most importantly, you should know that Comcast does not block access to any Web site or application, including peer-to-peer services like BitTorrent. Our customers use the Internet for downloading and uploading files, watching movies and videos, streaming music, sharing digital photos, accessing numerous peer-to-peer sites, VOIP applications like Vonage, and thousands of other applications online. We do the port 25 blocking so that we can verify that users are sending email through our servers that is Comcast email accounts only. Landon_(Fri Jul 18 2008 10:39:44 GMT-0700 (PDT))> Regardless, Comcast is blocking outbound port 25 to my corporate e-mail servers. Caleb(Fri Jul 18 2008 13:39:25 GMT-0700 (PDT))> They should have a webmail version that you are able to use when not at the office. We cannot unblock the PORT 25. I am sorry for any inconvenience this may have caused you.
Polymorphism in Erlang
26 Jun 2008, 14:59 PDTOver the weekend, I wrote my first Erlang application of any size -- an XML-RPC server that supplies geocoding data from a PostGIS database running the tiger_geocoder.
With the desire to support arbitrary geocoder data sources (including a mock data source for unit tests), I set out to discover how to best implement polymorphism in Erlang:
public interface Geocoder {
public Geometry geocode (final String address) throws GeocoderException;
}
Process Polymorphism
In Erlang, threads (processes, in Erlang parlance) communicate via message passing. In this, processes are polymorphic -- any message may be sent to any process, allowing for handling by disparate implementations.
However, there is a limitation to leveraging this method. Individual processes handle messages serially, not concurrently. If your geocoder implementation does not require serialized execution, then relying on processes constrains the natural concurrency of your implementation.
Polymorphic Function Dispatch
In Erlang, code is organized into modules, with each module declaring a set of exported functions. While modules are analogous to objects, Erlang's modules differ in their inability to maintain any state (a small fib -- explained in the Parameterized Modules section below).
Modules themselves are first-class entities in Erlang -- references may be assigned to variables, and thus a limited form of stateless polymorphism introduced:
Eshell V5.6.2 (abort with ^G) 1> Mod = lists. lists 2> Mod:reverse([1, 2, 3, 4]). [4,3,2,1]
Like Java classes, Erlang modules may declare their implementation of a behavior (ie, an interface). Validated at compile time, behaviors define the functions that a module should implement. By combining behaviors and module polymorphism, we can achieve functionality analogous to Java interfaces.
First, let's define a geocoder behavior that dispatches function calls to the concrete implementation. A behavior may be defined by implementing a module which exports a behaviour_info function:
-module(geocoder).
-export([behaviour_info/1]).
%% A geocoder instance.
%%
%% @type geocoder() = #geocoder {
%% module = term(),
%% state = term()
%% }
-record(geocoder, {
module,
state
}).
% Return a list of required functions and their arity
behaviour_info(callbacks) -> [{geocode, 2}];
behaviour_info(_Other) -> undefined.
% Create a new geocoder instance with the provided Module and State.
% This method should not be called directly -- use the concrete implementation
create(Module, State) ->
Geocoder = #geocoder { module = Module, state = State },
{ok, Geocoder}.
% Geocode an address string, returning the normalized geocode_address()
% record and WGS84 geocode_coordinates().
geocode(Geocoder, AddressString) ->
(Geocoder#geocoder.module):geocode(Geocoder#geocoder.state, AddressString).
Now we can define our concrete implementation that implements the geocoder behavior -- a mock geocoder used for unit testing:
-module(geocoder_mock).
-behavior(geocoder).
% Create a new instance
create() ->
geocode_source:create(?MODULE, undefined).
geocode(State, AddressString) ->
{ok, #geocode_coordinates{latitude = "43.162523", longitude = "-87.915512"}}.
To use our mock geocoder, we first construct an instance, and then dispatch all calls through the geocoder module:
Geocoder = geocoder_mock:create(), Coordinates = geocoder:geocode(Geocoder, "565 N Clinton Drive, Milwaukee, WI 53217").
Experimental: Parameterized Modules
Parameterized modules are a new addition to Erlang, and remain undocumented and experimental. It's worth reading Richard Carlsson's paper, Parameterized modules in Erlang.
In short, using parameterized modules one can construct a module that maintains (immutable) instance state:
M = geocoder_mock:new("Your mock geocoder").
There are a few downsides to this functionality:
- Only one module constructor may be provided -- pattern matching is not supported.
- Class methods are not supported. Only 'new' may be called on a parameterized module prior to instantiation.
- The functionality is experimental, undocumented, and subject to change.
PLDatabase - Simple Objective-C SQLite Library
07 May 2008, 11:03 PDTJonathan and I just put together Plausible Database, a small Objective-C SQLite library for our iPhone development. The API is intended to allow support for additional databases, but SQLite is clearly the primary target on the phone.
The 1.0 "preview release", including doxygen-generated API documentation, is available via Google Code (BSD license). The code has 100% unit test coverage, and should work for both Mac OS X and NDA-covered SDKs of an indeterminate nature. It's a relatively small bit of code, but we'd appreciate any feedback on the API or implementation -- including your thoughts on supporting future database back-ends, such as PostgreSQL. The API was inspired by public domain SQLite code (FMDB) from Gus Mueller of Flying Meat.
We have used the library to implement a small transactional schema migration library for our applications -- SQLite has a super handy per-database "user_version" which can be used for this.
Here are some usage examples:
/* Create and open an in-memory database */
PLSqliteDatabase *db = [[PLSqliteDatabase alloc] initWithPath: @":memory:"];
if (![db open])
NSLog(@"Could not open database");
/* Create a table and add some data */
if (![db executeUpdate: @"CREATE TABLE example (id INTEGER)"])
NSLog(@"Table creation failed");
if (![db executeUpdate: @"INSERT INTO example (id) VALUES (?)", [NSNumber numberWithInteger: 42]])
NSLog(@"Data insert failed");
/* Execute a query */ NSObject*results = [db executeQuery: @"SELECT id FROM example WHERE id = ?", [NSNumber numberWithInteger: 42]]; while ([results next]) { NSLog(@"Value of column id is %d", [results intForColumn: @"id"]); } /* Failure to close the result set will not leak memory, but may * retain database resources until the instance is deallocated. */ [results close];
Porting Java 6 to FreeBSD Sparc
03 Feb 2008, 22:16 PSTOver the weekend I implemented an initial port of Java 6 to FreeBSD/Sparc64, primarily as a learning exercise -- I wanted to see how difficult it is to port Java to a platform where both the processor and operating system are already independently supported.
landonf@conpanna:bsd-sparc> uname -s -m FreeBSD sparc64 landonf@conpanna:bsd-sparc> ./bin/java -server Hello Hello, World
I believe this is the first port of the Sparc JVM to a non-Solaris system, and the work should be applicable to supporting other operating systems, such as NetBSD or Linux Sparc systems. This article will discuss the steps I took, with the hope of aiding future porters.
The JRL-licensed code can be downloaded here: patch-java6-freebsd-sparc-1.gz
By downloading these binaries or source code, you certify that you are a Licensee in good standing under the Java Research License of the Java 2 SDK, and that your access, use, and distribution of code and information you may obtain at this site is subject to the License. To ensure compliance, downloading requires "click-through" authentication:
- Username: 'jrl'
- Password: 'I am a Licensee in good standing'
Bootstrap Environment
Building Java requires Java, which is a catch-22 when you're bootstrapping an unsupported system. To work around this, I used an idea (and scripts) suggested by Havard Eidnes: I set up a second Linux system running Sun's Java, and then mounted my FreeBSD build directory at the exact same path on the Linux machine.
Havard's scripts ssh to the bootstrap host and run the Java commands there. The source files are read from the NFS build tree, and the output files are written back.
You can download my slightly modified version of Havard's scripts here: boot-java.tar.gz. Any bugs are surely my own. To use the scripts, set the following environmental variables:
- JAVA_BOOTHOST - The host to which the scripts will SSH
- JAVA_BOOTDIR - The full path to the java installation on the JAVA_BOOTHOST
When calling make, you must also ALT_BOOTDIR to the boot-java path (eg, $HOME/boot-java).
Getting it Running
I started by running 'make' and filling in the blanks -- the best approach is to copy liberally from existing platform implementations. In most cases, I borrowed the solaris-sparc implementation, and merged in code from the bsd-amd64 counterpart:
- Add architecture detection to your operating system's hotspot Makefile (eg, hotspot/build/bsd/Makefile)
- Add a new platform description file (try copying an existing one) (eg, hotspot/build/bsd/platform_sparc)
- Add a new platform make file (hotspot/build/bsd/makefiles/sparcv9.make)
- Copy the os_cpu implementation from an existing implementation (hotspot/src/os_cpu/solaris_sparc -> hotspot/src/os_cpu/bsd_sparc)
- Implement CPU capability detection in hotspot/src/cpu/sparc/vm/vm_version_sparc.cpp
Nearly all the new code needed to be added to hotspot/src/os_cpu/bsd_sparc. I took an iterative approach, starting from the Solaris code, merging in BSD-specific code, and attempting to build the result. Except for the slow machine I was working with (400Mhz!), merging in the BSD code was a fairly swift process.
Sun Studio vs. GCC
Sun builds the Solaris VM using the Sun Studio toolchain, which is not fully compatible with GCC. I had trouble with gcc 3.4, and eventually settled on 4.0, which worked almost perfectly, barring three issues.
First, gcc defines 'sparc' as a standard preprocessor macro. You can guess how well that works while compiling a sparc-related code; passing the -ansi flag disables the define.
Secondly, gcc does not support passing non-const objects as a reference parameter, while Sun Studio allows it. Relying on this is non-standard, but easily fixed -- see 'Reference to a non-const object cannot be initialized with an r-value of that object'.
Lastly, I had to rewrite the Sun Studio inline assembler template (hotspot/src/os_cpu/solaris_sparc/vm/solaris_sparc.il) in standard assembler. A good discussion of the differences between Studio's inline assembler and GCC-style assembly can be found at Alfred Huang's blog. This was straight-forward -- here's an example:
.inline _Atomic_swap32, 2 .volatile swap [%o1],%o0 .nonvolatile .end
Re-written as:
.global _Atomic_swap32
.align 32
_Atomic_swap32:
swap [%o1],%o0
retl
nop
SoyLatte: Release 1.0.2
03 Feb 2008, 21:03 PSTI'm happy to announce another update for SoyLatte, containing a number of minor improvements. Work also progresses on the feature branch, where I'm focusing on native graphics support.
Changes
Bug fixes:
- The x86_64 JVM now correctly handles divide by zero. More info...
- The JVM crash log now correctly prints all loaded libraries, using _dyld_get_image_name() and _dyld_get_image_vmaddr_slide().
- Only transfer the number of bytes requested, not the entire file in FileChannelImpl.transferTo(). Bug fixed upstream by Greg Lewis, and reported by Michael Allman.
- On Mac OS X 10.4, CrashReporter will write a crash log for all 'fatal' signals, including signals caught and handled by the JVM. The JVM now disables CrashReporter's mach task handler, preventing CrashReport from writing unnecessary crash reports.
Download
Binaries, source, build, and contribution instructions are all available from SoyLatte Project Page
Java Signal Handling: Turning SIGFPE into java.lang.ArithmeticException
03 Feb 2008, 20:38 PSTIntroduction
When implementing a virtual machine such as Java's, it's necessary (and sometimes beneficial) to handle some unexpected conditions by allowing the errors to occur, and then catching the resultant signals delivered by the operating system. Take, for example, divide by zero:
int i = 5 / 0;
Hotspot could generate code to check divisor == 0 before every division operation:
cmpl $0, %ecx // Is the divisor 0 je L2 // Jump to div-by-zero handler movl %edx, %eax // store in divisor eax sarl $31, %edx // clear edx, leaving the sign bit idivl %ecx // divide edx:eax / ecx
But instead, Hotspot takes a leap of faith -- since programs should rarely divide by zero, Java emits the division instruction, and if the divisor is 0, relies on its signal handler to interpret the resultant SIGFPE:
if (sig == SIGFPE && (info->si_code == FPE_INTDIV || info->si_code == FPE_FLTDIV)) {
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_DIVIDE_BY_ZERO);
On Friday, I received a bug report for the x86_64 version of SoyLatte from Jibril Gueye. As it turns out, divide by zero errors were not being handled in the 64-bit VM, and instead of throwing an ArithmeticException, Java was unceremoniously crashing:
landonf@max> /usr/local/soylatte16-amd64-1.0.1/bin/java Test # # An unexpected error has been detected by Java Runtime Environment: # # SIGFPE (0x8) at pc=0x0000000101886ba8, pid=35000, tid=0x301000
After fixing the issue, I thought it would be interesting to discuss how Java handles signals, and why the SIGFPE handler didn't work:
Signal Registration and Delivery
After the JVM has parsed its command line arguments, the os::init_2() operating-specific method is called. This method is responsible for performing any remaining OS-specific initialization tasks, such as the registration of signal handlers. The BSD implementation can be found in hotspot/src/os/bsd/vm/os_bsd.cpp.
At this time, an architecture-specific JVM_handle_bsd_signal() function is registered as a handler for SIGSEGV, SIGPIPE, SIGBUS, SIGILL, and SIGFPE. (See signal.h for descriptions.) When a divide by zero error occurs, SIGFPE is delivered to the process, and the JVM's JVM_handle_bsd_signal() is called.
The signal handler is registered using sigaction, with the SA_SIGINFO flag set. According to the Single Unix Specification, "If SA_SIGINFO is set and the signal is caught, the signal-catching function will be entered as:"
void func(int signo, siginfo_t *info, void *context);
Upon a divide by zero, the provided siginfo structure contains a 'si_code' member set to FPE_INTDIV:
typedef struct __siginfo {
int si_signo; /* signal number */
int si_errno; /* errno association */
int si_code; /* signal code */
...
} siginfo_t;
With this information, our Java_handle_bsd_signal() implementation can check the signal number and code, and throw an ArithmeticException:
if (sig == SIGFPE &&
(info->si_code == FPE_INTDIV || info->si_code == FPE_FLTDIV)) {
stub = SharedRuntime::continuation_for_implicit_exception(thread,
pc, SharedRuntime:: IMPLICIT_DIVIDE_BY_ZERO);
SharedRuntime::continuation_for_implicit_exception() returns the entry point to Hotspot-generated code that sets up Java exception dispatching in the current frame. When the signal handler is finished, it saves the program counter and jumps to this stub, which handles setting up the frame and throwing the ArithmeticException.
Mac OS X and FPE_INTDIV
After receiving the bug report, I decided to take a look at Mac OS X's kernel signal handling code. On Darwin, the sendsig function handles creation and dispatch of UNIX signals to user processes. Looking at sendsig, we see that Mac OS X doesn't set si_code to FPE_INTDIV, and as such, JVM_handle_bsd_signal() can't decipher the signal:
case SIGFPE:
#define FP_IE 0 /* Invalid operation */
#define FP_DE 1 /* Denormalized operand */
#define FP_ZE 2 /* Zero divide */
#define FP_OE 3 /* overflow */
#define FP_UE 4 /* underflow */
#define FP_PE 5 /* precision */
if (ut->uu_subcode & (1 << FP_ZE)) {
sinfo64.si_code = FPE_FLTDIV;
} else if (ut->uu_subcode & (1 << FP_OE)) {
sinfo64.si_code = FPE_FLTOVF;
} else if (ut->uu_subcode & (1 << FP_UE)) {
sinfo64.si_code = FPE_FLTUND;
} else if (ut->uu_subcode & (1 << FP_PE)) {
sinfo64.si_code = FPE_FLTRES;
} else if (ut->uu_subcode & (1 << FP_IE)) {
sinfo64.si_code = FPE_FLTINV;
} else {
printf("unknown SIGFPE code %ld, subcode %lx\n",
(long) ut->uu_code, (long) ut->uu_subcode);
sinfo64.si_code = FPE_NOOP;
}
break;
As you can see, there's no code to handle FPE_INTDIV, si_code is set to FPE_NOOP, and an error message is printed to the console. A quick check of dmesg shows that our kernel is indeed printing "unknown SIGFPE" when Java attempts a divide by zero:
sudo dmesg | grep SIGFPE unknown SIGFPE code 1, subcode 0
This is suboptimal behavior, so I've filed a bug (5708523 - xnu sendsig() does not set siginfo->si_code = FPE_INTDIV for SIGFPE). In the meantime, a fix is necessary.
You may recall the 'void *context' argument passed to the signal handler. On Mac OS X, this is actually a pointer to ucontext structure. The ucontext contains the full context of the thread's state, at the time of the exception. This includes the program counter -- a register containing the address of the instruction that caused the exception.
Since we have the address of the instruction, we can determine what the instruction is. Once we know what the instruction is, we determine if it could have caused an integer divide by zero exception. This fix was used previously in Java to support Linux/x86 1.x kernels, which also did not set si_code.
To determine what instruction(s) could cause a FPE_INTDIV on 64-bit x86 machines, I consulted the Intel 64 and IA-32 Architectures Software Developer's Manuals -- the answer is idiv and idivl. Also, on amd64 machines, most operations remain 32-bit, and 64-bit operations require the a REX prefix. We'll need to skip the prefix if it exists.
Now we can add code to examine the program counter in JVM_handle_bsd_signal():
// HACK: si_code == FPE_INTDIV is not supported on Mac OS X (si_code is set to FPE_FPE_NOOP).
// See also xnu-1228 bsd/dev/i386/unix_signal.c, line 365
// Filed as rdar://5708523 - xnu sendsig() does not set siginfo->si_code = FPE_INTDIV for SIGFPE
} else if (sig == SIGFPE && info->si_code == FPE_NOOP) {
int op = pc[0];
// Skip REX
if ((pc[0] & 0xf0) == 0x40) {
op = pc[1];
} else {
op = pc[0];
}
// Check for IDIV
if (op == 0xF7) {
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime:: IMPLICIT_DIVIDE_BY_ZERO);
} else {
// TODO: handle more cases if we are using other x86 instructions
// that can generate SIGFPE signal.
tty->print_cr("unknown opcode 0x%X with SIGFPE.", op);
fatal("please update this code.");
}
With the fix in place, Java throws the expected ArithmeticException:
landonf@max:~> java Test
Exception in thread "main" java.lang.ArithmeticException: / by zero
at Test.main(Test.java:3)
Fixing ptrace(pt_deny_attach, ...) on Mac OS X 10.5 Leopard
22 Jan 2008, 03:58 PSTIntroduction
PT_DENY_ATTACH is a non-standard ptrace() request type that prevents a debugger from attaching to the calling process. Adam Leventhal recently discovered that Leopard extends PT_DENY_ATTACH to prevent introspection into processes using dtrace. I hope Adam will forgive me for quoting him here, but he put it best:
This is antithetical to the notion of systemic tracing, antithetical to the goals of DTrace, and antithetical to the spirit of open source. I'm sure this was inserted under pressure from ISVs, but that makes the pill no easier to swallow.
This article will cover disabling PT_DENY_ATTACH for all processes on Mac OS X 10.5. Over the previous few years, I've provided similar hacks for both Mac OS X 10.4, and 10.3.
To be clear: this work-around is a hack, and I hold that the correct fix is the removal of PT_DENY_ATTACH from Mac OS X.
How it Works
In xnu the sysent array includes function pointers to all system calls. By saving the old function pointer and inserting my own, it's relatively straight-forward to insert code in the ptrace(2) path.
However, with Mac OS X 10.4, Apple introduced official KEXT Programming Interfaces, with the intention of providing kernel binary compatibility between major operating system releases. As a part of this effort, the sysent array's symbol can not be directly resolved from a kernel extension, thus removing the ability to easily override system call. In 10.4, I was able to work-around this with the amusing temp_patch_ptrace() API. This API has disappeared in 10.5.
For Leopard, I decided to find a public symbol that is placed in the data segment, nearby the sysent array. In the kernel's data segment, nsysent is placed (almost) directly before the sysent array. By examining mach_kernel I can determine the offset to the actual sysent array, and then use this in my kext to patch the actual function. To keep things safe, I added sanity checks to verify that I'd found the real sysent array.
Each sysent structure has the following fields:
struct sysent {
int16_t sy_narg; /* number of arguments */
int8_t reserved; /* unused value */
int8_t sy_flags; /* call flags */
sy_call_t *sy_call; /* implementing function */
sy_munge_t *sy_arg_munge32; /* munge system call arguments for 32-bit processes */
sy_munge_t *sy_arg_munge64; /* munge system call arguments for 64-bit processes */
int32_t sy_return_type; /* return type */
uint16_t sy_arg_bytes; /* The size of all arguments for 32-bit system calls, in bytes */
};
The "sy_call" field contains a function pointer to the actual implementing function for a given syscall. If we look at the actual sysent table, we'll see that the first entry is "SYS_nosys":
__private_extern__ struct sysent sysent[] = {
{0, 0, 0, (sy_call_t *)nosys, NULL, NULL, _SYSCALL_RET_INT_T, 0},
To narrow down the haystack, we'll find the address of the nsysent variable, and then search for the nosys function pointer -- as shown above, nosys should be the first entry in the sysent array.
nm /mach_kernel| grep _nsysent 00502780 D _nsysent
nm /mach_kernel| grep T\ _nosys 00388604 T _nosys
Here is a dump of the mach_kernel, starting at 0x502780. You can see the value is 0x01AB, or 427 -- by looking at the kernel headers, we can determine that this is the correct number of syscall entries. 33 bytes after nsysent, we see 0x388604 (in little-endian byte order) -- this is our nosys function pointer. After counting the size of the sysent structure fields, we can determine that the the sysent array is located 32 bytes after the nsysent variable address. (On PPC, it's directly after).
otool -d /mach_kernel 00502780 ab 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00502790 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 005027a0 00 00 00 00 04 86 38 00 00 00 00 00 00 00 00 00
Once we have the address of the array, we can find the SYS_ptrace entry and substitute our own ptrace wrapper:
static int our_ptrace (struct proc *p, struct ptrace_args *uap, int *retval)
{
if (uap->req == PT_DENY_ATTACH) {
printf("[ptrace] Blocking PT_DENY_ATTACH for pid %d.\n", uap->pid);
return (0);
} else {
return real_ptrace(p, uap, retval);
}
}
kern_return_t pt_deny_attach_start (kmod_info_t *ki, void *d) {
...
real_ptrace = (ptrace_func_t *) _sysent[SYS_ptrace].sy_call;
_sysent[SYS_ptrace].sy_call = (sy_call_t *) our_ptrace;
...
}
Download
You can download the kext source here (sig).
Buyer beware: This code has only seen limited testing, and your mileage may vary. If something goes wrong, sanity checks should prevent a panic, and the module will fail to load.
If the module loads correctly, you should see the following in your dmesg output:
[ptrace] Found nsysent at 0x502780 (count 427), calculated sysent location 0x5027a0. [ptrace] Sanity check 0 1 0 3 4 4: sysent sanity check succeeded. [ptrace] Patching ptrace(PT_DENY_ATTACH, ...). [ptrace] Blocking PT_DENY_ATTACH for pid 82248.
Note: To access the nsysent symbol, the kext is required to declare a dependency on a specific version of Mac OS X. When updating to a new minor release, it should be sufficient to change the 'com.apple.kernel' version in the kext's Info.plist. I've uploaded a new version of the kext with this change, but I won't provide future updates unless a code change is required.
<key>OSBundleLibraries</key>
<dict>
<key>com.apple.kernel</key>
<string>9.2.0</string>
</dict>
Much thanks to Ryan Chapman for noting this issue, and testing the kext with 10.5.2.
SoyLatte: Release 1.0.1
06 Jan 2008, 19:26 PSTMinor Bugfix
This release fixes a name resolution bug reported by Leif Nelson of LLNL.
- If java.net.preferIPv4Stack is set to true, getaddrinfo() makes (time consuming) MDNS SRV requests
I tracked this down to this copy/paste bug in resolver code:
error = getaddrinfo(hostname, "domain", &hints, &res);
The service argument should have been NULL.
Download
Binaries, source, build, and contribution instructions are all available from SoyLatte Project Page
Implementing a Better DNS Dead Drop
06 Jan 2008, 19:15 PSTdead drop (n): A dead drop or dead letter box, is a location used to secretly pass items between two people, without requiring them to meet.
The Original DNS Dead-Drop
Two years ago, I implemented a DNS-based dead-drop, based on an idea presented by Dan Kaminisky in Attacking Distributed Systems: The DNS Case Study.
Using a recursive, caching name server, coupled with a wildcard zone, it's possible to implement double-blind data transfer. In each DNS query, 7 bits are reserved for a number of flags, one of which is the Recursion Desired (RD) flag. If set to 0, the queried DNS server will not attempt to recurse -- it will only provide answers from its cache.
Combine this with a wildcard zone and it's possible to signal bits (RD on), and read them (RD off). To set a bit to 1 the sender issues a query with the RD bit on. The wildcard zone resolves all requests, including this query. The receiver then issues a query for the same hostname, with the RD bit off. If the bit is 1, the query will return a valid record. If the bit is 0, no record will be returned.
So, it's easy to signal a single bit, but what if you want to share more than 1 bit of data? This requires both sides to compute a list of records -- one record for every bit of data we wish to send. In my implementation, I chose to do this with a pre-shared word list and initialization vector (IV). Given the same word list and IV, both sender and receiver can independently compute an identical mapping of words to bit positions. The sender can then signal the '1' bits, and the receiver can query all bits.
Hiding the Trail: Using TTL to Signal Bits
To avoid suspicion, a good dead-drop mechanism should not appear unusual to an outside observer. The RD flag is unusual, and a signature to detect its use can easily be added to intrusion detection systems. It would be considerably more sneaky to use a signaling mechanism that relied on more normal-appearing DNS queries.
This is where the time-to-live (TTL) value can be used. When returning query results, many recursive DNS servers include a TTL -- the number of seconds before the recursive name server will purge the record from its cache. The TTL begins decrementing as soon as a record is cached. Therefor, newer lookups with have a higher TTL than older lookups. Using this property, it is possible to determine if a record was previously cached, and thus signal bits without relying on the RD flag.
To communicate, the sender and receiver need to pre-share a word list, an initialization vector (IV), the IP of a recursive nameserver, a wildcard domain, and a communications window (time of day). Here's how the protocol works:
Sender:
- Step 1: Split the message into individual bits.
- Step 2: Permute the word list in a reproducible fashion using the shared IV.
- Step 3: Encode the length of your message as an 8 bit unsigned value, and prepend the length to your message data.
- Step 4: Each word in the ordered word list corresponds to a single bit of your message. Generate a valid hostname for each bit by combining each word with the wildcard DNS zone
- Step 5: For each bit that is 1, do a recursive lookup against the shared nameserver for the corresponding wildcarded hostname.
Receiver:
- Step 1: Permute the word list in a reproducible fashion using the shared IV.
- Step 2: Each word in the ordered word list corresponds to a single bit of the message. Generate a valid hostname for each bit by combining each word with the wildcard DNS zone.
- Step 3: Acquire the message length by doing recursive lookup against the shared nameserver for the first 8 bits of the message. Names with high TTLs are 0, names with lower TTLs are 1. Remember that the sender did not issue requests for "0" bits, so all 0 bits will have higher TTLs.
- Step 4: For each word in the word list, do a recursive lookup against the shared nameserver for the remainder of the message. Perform the same TTL heuristics to determine bit values.
- Step 5: Reconstruct the message from the individual bits.
Download
You can download a copy of NSDK here. It's written in Python, and depends on the dnspython library.
The implementation is a proof-of-concept -- the TTL heuristic is very simple, and you'll certainly see bit errors in longer messages. I enjoyed the "Bourne Identity" books way too much, and this is all meant in fun.
Usage
nsdk.py [dns IP] [wildcard domain] [word list] [iv] <message>
Each bit of your message requires at least one DNS query. I strongly suggest testing this implementation against name servers and zones that you control.
To send a message:
./nsdk.py 10.0.0.1 wildcard.example.com /usr/share/dict/words 42 "The crow flies at midnight" Message sent successfully!
To receive the message:
./nsdk.py 10.0.0.1 wildcard.example.com /usr/share/dict/words 42 Read 208 bits from DNS server The Secret Message: The crow flies at midnight