XSmallTest Test DSL
06 Jun 2014, 08:46 PDTI just published beta sources for XSmallTest (XSM), a minimal single-header implementation of a test DSL that generates test cases compatible with Xcode's XCTest:
#import "XSmallTest.h"
xsm_given("an integer value") {
int v;
xsm_when("the value is 42") {
v = 42;
xsm_then("the value is the answer to the life, the universe, and everything") {
XCTAssertEqual(42, v);
}
}
}
I'll be gradually migrating some of my projects over; you can find the source code here.
PLPatchMaster: Swizzling in Style
17 Feb 2014, 14:56 PSTIntroduction
Last year, I wrote a swizzling API for my own use in patching Xcode; I wanted an easy way to define new method patches, and the API wound up being pretty nice:
[UIWindow pl_patchInstanceSelector: @selector(sendEvent:) withReplacementBlock: ^(PLPatchIMP *patch, UIEvent *event) {
NSObject *obj = PLPatchGetSelf(patch);
// Ignore 'remote control' events
if (event.type == UIEventTypeRemoteControl)
return;
// Forward everything else
return PLPatchIMPFoward(patch, void (*)(id, SEL, UIEvent *), event);
}];
In light of Mattt Thompson's post on Method Swizzling today, I figured I'd brush it off, port it to armv7/armv7s/arm64, and share it publicly.
PLPatchMaster uses the same block trampoline allocator I originally wrote for PLBlockIMP, along with a set of custom trampolines.
It's similar to imp_implementationWithBlock() in implementation and efficiency; rather than simply re-ordering 'self' and '_cmd', we pass in enough state to allow forwarding the message to the original receiver's implementation.
Use it at your own risk; swizzling in production software is rarely, if ever, a particularly good idea.
Advanced Use
The library can also be used to register patches to be applied to classes that have not yet been loaded:
[[PLPatchMaster master] patchFutureClassWithName: @"ExFATCameraDeviceManager" withReplacementBlock: ^(PLPatchIMP *patch, id *arg) {
/* Forward the message to the next IMP */
PLPatchIMPFoward(patch, void (*)(id, SEL, id *));
/* Log the event */
NSLog(@"FAT camera device ejected");
}];
PLPatchMaster registers a listener for dyld image events, and will automatically swizzle the target class when its Mach-O image is loaded.
Source Code
The soure code is available via the official repository, or via the GitHub mirror.
Reliable Crash Reporting
14 Sep 2011, 16:09 PDTIntroduction
PLCrashReporter is a standalone open-source library for generating crash reports on iOS. When I first wrote the library in 2008, it was the only option for automatically generating and gathering crash reports from an iOS application. Apple's iOS crash reports were not available to developers, and existing crash reporters — such as Google's excellent Breakpad — were not supported on iOS (Breakpad still isn't). Since that time, quite a few crash reporters and crash reporting services have appeared: Apple now provides access to App Store crash reports, a number of 3rd-party products and services were built on PLCrashReporter (such as HockeyApp, JIRA Mobile Connect), and some services have chosen to write their own crash reporting library (TestFlight, Airbrake, and others).
Despite this obvious interest in adopting crash reporting from iOS developers, there has remained little understanding of the complexities and difficulties in implementing a reliable and safe crash reporter, and many of the custom crash reporting libraries have been implemented improperly. It's my intention to explore what makes crash reporting difficult (especially on iOS), and provide real-world examples of how an impoperly written crash reporter can fail — sometimes with little fanfare, and sometimes with surprising consequences.
A Hostile Environment
Implementing a reliable and safe crash reporter on iOS presents a unique challenge: an application may not fork() additional processes, and all handling of the crash must occur in the crashed process. If this sounds like a difficult proposition to you, you're right. Consider the state of a crashed process: the crashed thread abruptly stopped executing, memory might have been corrupted, data structures may be partially updated, and locks may be held by a paused thread. It's within this hostile environment that the crash reporter must reliably produce an accurate crash report.
To reliably execute within this hostile environment, code must be "async-safe": it must not rely on external, potentially inconsistent state. More concretely, this means that a crash reporter must avoid APIs that have not been written explicitly to be executed with a signal handler, in a potentially crashed process. This excludes everything from malloc — the heap may have been corrupted, or partially updated — to Objective-C — locks may be held in the runtime, or data structures might be partially initialized. In fact, there's so little that you can do safely within a signal handler, it's much easier to define what you *can* do safely — a minimum number of system calls and APIs are defined to be async-safe, and those are the only APIs you can reliably call.
Thus, to be reliable and safe, a crash reporter must be written with async-safety in mind, eliminating or minimizing the risk inherent in operating within a hostile and corrupt environment. At this point, you might ask what I mean by "reliable and safe" — after all, if the process has already crashed, what's the worst that could happen? It crashes again? In fact, there's quite a bit that can go wrong, largely depending on the non-async-safe APIs that an unreliable crash reporter might rely on.
First, do no harm
The mission of a crash reporter is simple: report crashes, and provide enough information to debug them. As it turns out, if you know how to read the report, just about everything you need to debug nearly all crashes can be found in the backtraces, register state, and a bit of intuition about your own code (look for a future blog post on this subject).
However, a crash reporter should never make things worse — I'll cover three major ways it can do that:
- Relying on non-async-safe APIs: This can deadlock the process and cause a hang, resulting in a failure to report the crash. In the pathological case, this can result in corruption of users' data.
- Using overly simple APIs like backtrace(3): Blinds the developer to specific problems --- such as a stack overflow -- by being unable to report them.
- Discarding crashed thread's register state: Providing incomplete crash reports makes it practically impossible to debug certain classes of crashes.
Let's explore these failure cases with some real world examples.
Failure Case: Async-Safety and Deadlocking Objective-C
One of the more likely failure modes when dealing with a non-async-safe APIs is a deadlock. Imagine that the application has just acquired a lock prior to crashing. If the crash reporter's implementation then attempts to acquire the same lock, it will wait forever: the crashed thread is no longer running and will never release the lock. When a deadlock like this occurs on iOS, the application will appear unresponsive for 10-20 seconds until the system watchdog terminates the process, or the user force quits the application.
It is possible to trigger such a deadlock simply by using Objective-C within the signal handler. The Objective-C runtime itself maintains a number of internal locks, and if a thread happens to hold a runtime lock when a crash occurs, any use of Objective-C in the crash reporter itself will trigger a deadlock. This is dependent on timing, however — for the purposes of a providing a simple test case, I've created a contrived example that will reliably demonstrate the deadlock on ARM and x86:
static void unsafe_signal_handler (int signo) {
/* Attempt to use ObjC to fetch a backtrace. Will trigger deadlock. */
[NSThread callStackSymbols];
exit(1);
}
int main(int argc, char *argv[]) {
/* Remove this line to test your own crash reporter */
signal(SIGSEGV, unsafe_signal_handler);
/* Some random data */
void *cache[] = {
NULL, NULL, NULL
};
void *displayStrings[6] = {
"This little piggy went to the market",
"This little piggy stayed at home",
cache,
"This little piggy had roast beef.",
"This little piggy had none.",
"And this little piggy went 'Wee! Wee! Wee!' all the way home",
};
/* A corrupted/under-retained/re-used piece of memory */
struct {
void *isa;
} corruptObj;
corruptObj.isa = displayStrings;
/* Message an invalid/corrupt object. This will deadlock crash reporters
* using Objective-C. */
[(id)&corruptObj class];
return 0;
}
If you run this code on iOS or the simulator, you'll reliably trigger a deadlock in any crash reporter using Objective-C in its signal handler. While this specific example is somewhat contrived for the sake of serving as reliable test case, any use of Objective-C or any other non-async-safe function in a signal handler has the potential to trigger such a deadlock, and should be avoided.
Failure Case: Async-Safety and Data Corruption
The risk of data corruption is a far more potent concern than a deadlock. There are a surprising number of ways that this can occur — but what might be the most likely (and dangerous) mechanism to trigger data corruption is the reentrant running of the application's event loop.
Some crash reporters attempt to submit the crash report over the network immediately upon program termination. This introduces an interesting failure mode: spinning the runloop to handle network traffic may also trigger execution of the application's own code, and the application is then free to attempt to write potentially corrupt user data.
Consider a Core Data-based application, in which a model object is updated, and then saved:
person.name = name; person.age = age; // a crash occurs here person.birthday = birthday; [context save: NULL];
At the time of the crash, the managed object context contains a partially updated record — certainly not something you want saved to the database. However, if the crash reporter then proceeds to reentrantly run the application's runloop, any network connections, timers, or other pending runloop dispatches in your application will also be run. If the application code dispatched from the runloop contains a call to -[NSManagedObjectContext save:], you'll write a partially updated record to the database, corrupting the user's data.
This approach of executing non-reentrant, non-async-safe code from a crash reporter is particularly dangerous. To avoid this, the signal handler can not make use of higher-level networking APIs at crash time, and crash report implementations must not attempt to submit a crash report until the application has started again.
If added to your UIApplicationDelegate, the following code will print a message to the console if your crash reporter spins the runloop after a crash has occurred:
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"APPLICATION CODE IS RUNNING - Crash reporter is spinning runloop");
});
*((int *)NULL) = 5; // trigger a crash
Failure Case: Stack Traces and Stack Overflow
There are two ways to implement backtrace support in a crash reporter (but only one of them is reliable):
- Use high-level APIs such as backtrace(3) or -[NSThread callStackSymbols] to fetch a stack trace for the current thread
- Implement custom stack walking to support fetching a backtrace for all threads (including the crashed thread)
The first solution is unreliable for a number of reasons, but the failure mode I'll be addressing here is a stack overflow. In the case of a stack overflow, a crash reporter that makes use of backtrace(3) or similar APIs will be entirely unable to report the crash. Here's a code example that will accidentally trigger an overflow:
/* A small typo can trigger infinite recursion ... */
NSArray *resultMessages = [NSMutableArray arrayWithObject: @"Error message!"];
NSMutableArray *results = [[NSMutableArray alloc] init];
for (NSObject *result in resultMessages)
[results addObject: results]; // Whoops!
NSLog(@"Results: %@", results);
If the crash reporter makes use of backtrace(3), this crash will not be reported. The reason is straight-forward: These backtrace APIs must execute on on the crashed thread's stack, but that stack just overflowed. There is is no stack space within which the crash reporter's signal handler can be run.
However, if the crash reporter uses sigaltstack() to correctly execute on a different stack, the backtrace will be empty — the signal handler is running on a new stack!
In PLCrashReporter, this was solved by implementing custom stack walking for the supported platforms. This requires more complexity, but in addition to supporting the generation of reports in the case of stack overflow, also allows the crash reporter to provide stack traces for all running threads.
Conclusion
Implementing a reliable crash reporter is difficult, and these are only a brief overview of the potential pitfalls and complexities involved. I think Mike Ash best described the complexity of signal handlers in Friday Q&A:
There is very little that you can do safely. There is so little that I'm not even going to discuss how to get anything done, because it's so impractical to do so, and instead will simply tell you to avoid using signal handlers unless you really know what you're doing and you enjoy pain.
While I can't claim that PLCrashReporter is perfect, great effort (and pain) have been expended in ensuring its reliability and correctness. If you're considering implementing your own ad-hoc reporter, I'd highly recommend reviewing the design decisions made in both Google Breakpad and PLCrashReporter, both of which are liberally licensed and may be included in any commercial and/or closed-source product.
As a developer considering the use of a crash reporter in your application, I hope this overview will provide a little more insight into their function (and design complexities), as well as providing you with some tools to evaluate the efficacy of the available solutions -- complex failure cases are often the time when you need accurate, reliable crash reporting the most.
Implementing imp_implementationWithBlock()
14 Apr 2011, 06:46 PDTIn iOS 4.3, Apple introduced a new API to support the use of blocks as Objective-C method implementations. The API provides similar functionality as Mike Ash's MABlockClosure, which uses libffi (or libffi-ios) to implement support for generating arbitrary function pointers that dispatch to a block.
However, Apple's new API differs from MABlockClosure in a few important ways:
- Only Obj-C IMP-compatible function pointers may be generated.
- No knowledge of the block's type signature is required (with some caveats we'll discuss below).
- The trampoline is lightweight (just a few instructions), this is faster than libffi-based dispatch as used by MABlockClosure.
Today, I'll be discussing how block-based message dispatch is implemented by Apple, and how you can implement your own similar, custom trampolines on iOS and Mac OS X. Additionally, I've posted PLBlockIMP on github. This project provides:
- An open-source implementation of imp_implementationWithBlock() for Mac OS X 10.6+ and iOS 4.0+ (ARM, i386, and x86-64).
- Generalized code to support automated generation of arbitrary trampoline pages on Darwin, based on the trampoline allocator I wrote for libffi-ios.
In addition to this article, Bill Bumgarner has written an excellent introduction to imp_implementationWithBlock, and if you need a refresher in objective message dispatch, Mike Ash has a more in-depth explanation here.
This work has been funded by my employer, Plausible Labs. We specialize in Mac OS X, iOS, and Android development and we're available for hire.
Creating Trampolines without Writable Code
The implementation of imp_implementationWithBlock() relies on trampolines to convert between Objective-C method calls and block dispatch. Trampolines are small pieces of code that, when called, perform some intermediary operations and then jump to the actual target destination. When you call imp_implementationWithBlock(), a function pointer to a trampoline is returned; it's this trampoline's responsibility to modify the function arguments and then jump to the actual code corresponding to the block's implementation.
Trampolines often require more information than can be derived from their function parameters -- such is the case with our IMP trampolines, which must have a pointer to the target block that they should call. Historically, this type of trampoline has generally been implemented through the use of writable code pages; the instructions are written to a PROT_EXEC|PROT_WRITE page at runtime, with any additional context information included directly in the generated code.
Unfortunately, iOS has instituted a restriction on the use of writable, executable pages (although there are signs that this may eventually be lifted), necessitating the use of an alternative mechanism for implementing trampoline-specific context data. While iOS does not allow the use of writable code, we can leverage a combination of vm_remap() and PC-relative addressing to implement configurable trampolines without writable code.
On Darwin, vm_remap() provides support for mapping an existing code page at new address, while retaining the existing page protections; using vm_remap(), we can create multiple copies of existing, executable code, placed at arbitrary addresses. If we generate a template page filled with trampolines at build time, we can create arbitrary duplicates of that page at runtime. This allows us to allocate an arbitrary number of trampolines using that template without requiring writable code:

Figure 1: vm_remap()
However, executable trampoline allocation only solves half the problem -- we still need a way to configure each trampoline.
The solution is PC-relative addressing. The processor's program counter register indicates the address of the currently executing instruction; PC-relative addressing uses the program counter to address memory relative to the currently executing instruction. When we remap our trampolines and then jump to them, each trampoline is executing at a unique address. If we then map a writable data page next to our trampoline page, we can use PC-relative addressing to load per-trampoline data from adjacent writable data page:
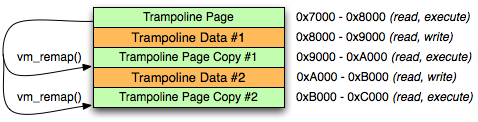
Figure 2: vm_remap() with writable data pages
Once a full page of trampolines are allocated, we simply need to provide the individual trampolines on request, and allocate additional pages if the pool of trampolines is exhausted. A full implementation of a trampoline allocator is available in PLBlockIMP; refer to pl_trampoline_alloc(), pl_trampoline_data_ptr(), and pl_trampoline_free().
To save space within our trampoline page, each individual trampoline saves the PC register, and then jumps to a common implementation at the start of the trampoline page. The ARM implementation of the individual trampoline stub is two instructions:
mov r12, pc b _block_tramp_dispatch;
IMP->Block Dispatch (self, _cmd, and Block)
As noted in Bill Bumgarner's article on imp_implementationWithBlock, every Objective-C method has two implicit, pointer-sized arguments at the head of the method's argument list: self, and _cmd. Likewise, block implementations also have an implicit first argument; the block literal, which maintains the block's reference count, bock descriptor, references to captured variables, and other block data.
When called, a trampoline returned by imp_implementationWithBlock() is responsible for re-ordering its arguments to match those required by the block's implementation: the 'self' argument must be moved to second argument slot (overwriting _cmd), and the block literal moved to the (now vacated) first argument slot.
However, there is one wrinkle that Bill didn't touch on: structure return values. On the current architectures supported by Darwin, functions that return structures by value may have an additional pointer at the start of their argument list. This pointer is used to provide the address on the caller's stack at which the structure return value should be written.
In the case where structure return (stret) calling conventions are used, the structure return pointer in the first argument slot must remain unmodified, the block literal argument must be in the second argument slot, and the self pointer in the third. This requires that imp_implementationWithBlock() provide two different trampoline implementations to support both calling conventions, and that the requisite trampoline type for a block be determined when imp_implementationWithBlock is called.
There is no way to determine from a raw function pointer whether a function requires stret calling conventions -- to work around this, Apple's compilers set an additional flag, BLOCK_USE_STRET, when emitting a block that requires the stret calling conventions. This flag may be used to easily determine the necessarily trampoline type for a block.
As described in the previous section, the individual trampolines save their PC address and then immediately jump to a shared implementation at the start of the trampoline page. That shared implementation re-orders the existing arguments, loads the block literal from its PC-relative configuration data, and then jumps to the block's implementation -- on ARM, our non-stret shared implementation looks like this:
_block_tramp_dispatch:
# trampoline address+8 is in r12 -- calculate our config page address
sub r12, #0x8
sub r12, #0x1000
# Set the 'self' argument as the second argument
mov r1, r0
# Load the block pointer as the first argument
ldr r0, [r12]
# Jump to the block pointer
ldr pc, [r0, #0xc]
Conclusion
While I still have my fingers crossed for PROT_EXEC|PROT_WRITE pages on iOS, vm_remap()-based trampolines can serve as a viable replacement for some tasks. If you have further questions, or ideas for other neat projects worth tackling, feel free to drop me an e-mail.
Objective-C Substrate Project
12 Sep 2006, 19:25 PDTFor the past few years, I've been fiddling with OpenDarwin's libFoundation in my spare time -- of which there is admitedly very little. For those new to the party, OpenDarwin's libFoundation project was an attempt to rewrite, refactor, and otherwise port the original libFoundation, as written by Ovidiu Predescu, Mircea Oancea, and Helge Hess, to Darwin. The end goals were simple. In order of importance:
- Have fun working on something silly in both scope and purpose, with little chance of success.
- Implement a light-weight, modern, well-written, unit tested, documented, mostly-complete, BSD-licensed Objective-C Foundation library.
The first goal was easily achieved, and surprisingly enough, I've been making some good progress on the second. With OpenDarwin's impending cessation of operation, I decided to set aside a week of my copious vacation time supplied by my generous employer to find OpenDarwin's libFoundation a new home, and tackle some difficult problems, including a unicode-aware NSString. I'm pleased to say that the week was well spent, and the newly christened Objective-C Substrate was the end result.